
AI-Powered Network Analysis Tools for Trust and Safety Researchers


Guido Rosa/Getty Images/Ikon Images
As research in trust and safety has accelerated in the past decade, researchers from different disciplines got busy creating tools and methodologies that best serve this area. The new developments have come from diverse set of disciplines since the problem that trust and safety teams are trying to solve are multidisciplinary in nature. As trust and safety teams work mostly with online social networks, it is imperative to understand that the action of an individual should not be seen in isolation to their position in a network in which they participate. A dynamic network analysis gives us way more information about the incident and integrate contexts in our research.
Today in this article I will explore a set of state of the art tools which are being created at Carnegie Mellon University. These tools facilitate trust and safety research from a network science perspective.
1) Organization Risk Analyzer (ORA) Software:
ORA is a powerful tool for analyzing and evaluating dynamic meta-networks. It is developed by the Center for Computational Analysis of Social and Organizational Systems (CASOS) at Carnegie Mellon University. This software is also extensively used at the Institute of Software research as well as the Center for Informed Democracy and Social Cyber-security (IDeaS).

The software includes hundreds of metrics for analyzing social networks, dynamic networks, and trails, as well as for identifying local patterns and comparing and contrasting networks, groups, and individuals from a dynamic meta-network perspective. The network analysis tool is being used extensively in academic circles at Carnegie Mellon to study how networks evolve over time and space and include features for moving between trail data (e.g. who was where when) and network data (e.g. who is connected to whom, who is connected to where).

This software can handle multi-mode, multi-plex, and multi-level networks. This allows a researcher to identify key players/ groups/vulnerabilities, as well as model network changes over time, and perform COA analysis. ORA’s analysis reports incorporate the principles from not only network theory, but also from social psychology, operations research, and management theory. Additionally, a set of measures has been developed at Carnegie Mellon for identifying "criticality" in this software. The software uses critical path algorithms that can detect people, skills or knowledge, and tasks that are critical from a performance and information security standpoint.

For my research, I use ORA Pro for dynamic meta-network assessment and analysis. For my first research paper, I compared the covid-19 disinformation networks in distinct partisan states. ORA allowed me to identify the densities of the network, and calculate the centralities of nodes (total-degree, out-degree, in-degree, betweenness, closeness, etc.) Through the software, I was able to identify the co-occurrence of different tweets and hashtags to follow how the narrative developed over time in each state.
For my second paper, I explored the presence of partisan bots on Twitter prior to the outing of the Pakistani Prime Minister and follow how different pro and against narratives were developed around him. In this paper, I used ORA again for stance detection. The stance detection report in ORA is based on research produced by Sumeet Kumar in the paper Social Media Analytics for Stance Mining A Multi-Modal Approach with Weak Supervision. This machine learning approach is grounded in social theory and provides a semi-supervised method that is based on co-training multiple stance classifiers (using different interaction modalities) and provides a better stance prediction model. I will be talking about the methodology in more detail in my coming articles.
All in all, personally, the software has been extremely useful for me in calculating dynamic network metrics, trail metrics, identifying group nodes/local patterns, and comparing, and contrasting networks from the perspective of a dynamic meta-network.

2) Bot Hunter:
In order to identify bots in our network we use Beskow and Carley’s BotHunter. The literature is available at Bot-hunter: A Tiered Approach to Detecting & Characterizing Automated Activity on Twitter. The tool calculates the bot probability of each actor based on meta data available about the individual.
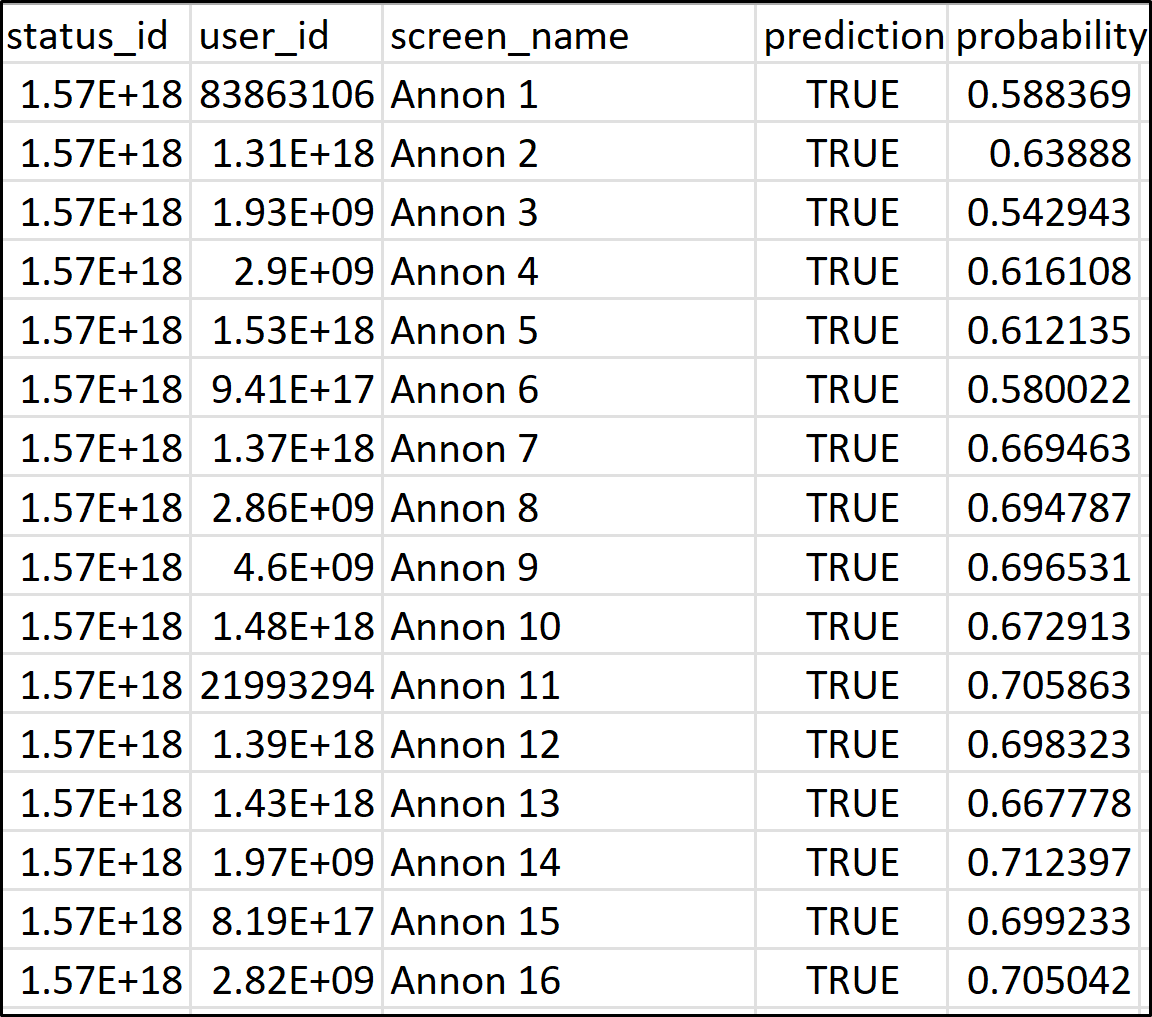
BotHunter is a “random forest regression model trained on labeled Twitter data sets … developed from forensic analyses of events with extensively reported bot activity, such as the attack against the Atlantic Council Digital Forensic Research Lab in 2017”. – Janice Blane
The Tier-1 BotHunter calculates the bot probability based on the following measures:
i) Network-level features: number of followers, number of friends, and number of favorites
ii) User-level features: screen name length, account age, default image, screen name entropy, total tweets, and source(binned)
iii) Tweet-level features: timing, is it a retweet, and the hashtag used
When compared with traditional bot probability measuring models it was seen that the random forest model performs better based on the AUC score of 0.994 shown below.

In our research, we use a bot probability score of 0.7 and higher to classify a user to be a bot so that we can limit the chance of false positives in our bot categorization. This value is based on Xian Ng, Robertson, and Carley’s ‘On the Stability of BotHunter Scores’ which recommends, “a threshold value of 0.70 for bot classification [using BotHunter]”.
3) NetMapper:
In order to extract linguistic cues from our dataset of tweets/content, we use the software NetMapper. The software was presented at the 11th International Conference on Social Computing, Behavioral-Cultural Modeling & Prediction and Behavior Representation in Modeling and Simulation by Carley and Reminga. The linguistic cues are metrics that are required to measure key features about the author such as the agent’s emotional state, general stance on a topic, etc. For the purpose of our research, we will use Net Mapper to create linguistic cues so that we can feed the information into ORA software to be able to run BEND Report – in an effort to understand what the social maneuvers the agents are trying to execute in their tweet.

Since we usually conduct our research on Twitter data, the NetMapper is able to work with the recent Twitter Version 2 Format of JSNOL data.
The linguistic cues created can then be used in ORA. This helps us create a BEND analysis for our dataset as shown below.
